


I have broader ideas for networking than just CALCnet. I'd like to implement a full networking stack and BSD sockets API, so then it can support CALCnet and other protocols like the one I described elsewhere on Cemetech. I would make that and other frame-level protocols compatible with CALCnet as far as the collision detection/avoidance header goes, but the rest of the protocol would be ignored by CALCnet-only calcs. This would allow multiple frame protocols on the same calculator network.




christop wrote:
I have broader ideas for networking than just CALCnet. I'd like to implement a full networking stack and BSD sockets API, so then it can support CALCnet and other protocols like the one I described elsewhere on Cemetech.
Indeed, I think you mentioned that at one time, and I completely forgot it. I think that's a great goal, and I'd love to help you design a protocol that would play nicely with CALCnet. 





I just came across something strange with Gnome Terminal while comparing its handling of escape codes to Punix's terminal. I set the character set to the British character set (using the sequence "ESC ( A") in Gnome Terminal, and the dollar sign in my prompt turned into the British pound sign. Doing the same in Punix, the hash sign in the prompt (I'm root in Punix) turned into the British pound sign, and the dollar sign is untouched. For a minute I thought I replaced the wrong character with the British pound sign, but in fact I didn't: http://vt100.net/docs/vt220-rm/table2-5.html http://vt100.net/docs/vt102-ug/chapter3.html#S3.6.3.9
So it seems like Gnome Terminal replaces the wrong character with the British pound sign. If you have access to Gnome Terminal and another terminal like xterm, try the following command:
If you have access to Gnome Terminal and another terminal like xterm, try the following command:
Code:
(Type Ctrl-V ESC in place of "^[")
xterm and Punix prints this:
Code:
Gnome Terminal prints this:
Code:
Fail.
So it seems like Gnome Terminal replaces the wrong character with the British pound sign.
Code:
echo '^[(A$# ^[(B$#'(Type Ctrl-V ESC in place of "^[")
xterm and Punix prints this:
Code:
$£ $#Gnome Terminal prints this:
Code:
£# $#Fail.
: TI Runner-Up")

odd catch.
iTerm and Terminal both print:
[thomas@Bombadil] ~ $ echo '^[(A$# ^[(B$#'
$# $#
xterm, however, prints (although trying to copy+paste produces the same as above):
[thomas@Bombadil] ~ $ echo '^[(A$# ^[(B$#'
$£ $#
iTerm and Terminal both print:
Quote:
[thomas@Bombadil] ~ $ echo '^[(A$# ^[(B$#'
$# $#
xterm, however, prints (although trying to copy+paste produces the same as above):
Quote:
[thomas@Bombadil] ~ $ echo '^[(A$# ^[(B$#'
$£ $#


On both KDE 3.5.x and KDE 4.6.x, when typing
Code:
from the terminal (Konsole), yields
Code:
Both konsole versions are set to emulate a xterm 4.x.x.
Code:
echo '^[(A$# ^[(B$#'from the terminal (Konsole), yields
Code:
$£ $#Both konsole versions are set to emulate a xterm 4.x.x.

haha,
Every once in a while I google my name with the current year to see what I can see.
I haven't seen the final code but I do feel obligated to comment on this bit:
Code:
The problem is that when doing multi-precision math spread across multiple words, the first add must be a regular add. Not an addx.
This will use whatever the extend flag happens to be at the time. Sometimes you get lucky, you might have cleared it by accident. However:
Swaps won't change it.
CLRs won't change it.
Multiplies won't change it.
Moving data in/out of ram or between registers won't change it.
Arithmetic on address registers won't change.
That pretty much covers all the instructions you've done up to that point. So you inherit whatever the xflag happens to be on the function entry.
-Samuel
Every once in a while I google my name with the current year to see what I can see.
I haven't seen the final code but I do feel obligated to comment on this bit:
Code:
addx.l -(%a1),-(%a0) /* wrong !! */
addx.l -(%a1),-(%a0)
addx.l -(%a1),-(%a0)
addx.w -(%a1),-(%a0)
The problem is that when doing multi-precision math spread across multiple words, the first add must be a regular add. Not an addx.
This will use whatever the extend flag happens to be at the time. Sometimes you get lucky, you might have cleared it by accident. However:
Swaps won't change it.
CLRs won't change it.
Multiplies won't change it.
Moving data in/out of ram or between registers won't change it.
Arithmetic on address registers won't change.
That pretty much covers all the instructions you've done up to that point. So you inherit whatever the xflag happens to be on the function entry.
-Samuel
Welcome to Cemetech, Nyall/Sam! Thanks for all your great work for the 68k calculators over the years. Perhaps I can entice you to Introduce Yourself when you get a chance? Christop, what's the current state of this project; does it continue to trot along?
Ay caramba! I almost always use a regular add first but didn't this time for some reason. Thanks for pointing that out, Samuel. I fixed it in my local copy.
It's nice to know that most instructions do not affect the extend flag, so I can use other instructions between addx instructions if I ever need to do so. I'll be sure to see which instructions do/don't affect extend.
Kerm, this project is still crawling along. I've had some family issues so I haven't had much time lately.
It's nice to know that most instructions do not affect the extend flag, so I can use other instructions between addx instructions if I ever need to do so. I'll be sure to see which instructions do/don't affect extend.
Kerm, this project is still crawling along. I've had some family issues so I haven't had much time lately.
Hmmmm...
I "fixed" the addx instructions by changing them to plain add instructions, but I didn't try to build the system with the changes. Apparently the regular add op-code can't take two operands of the form -(%ax) as addx can. I looked over my code some more and realized that the extend flag is cleared from an add instruction somewhere above the first addx in each case, so it turns out I can use addx without any problems after all.
Other than that, I don't have much else to report. I haven't had many opportunities to work on Punix for the last couple of months due to family issues. Hopefully I can pick it up again before too long.
I "fixed" the addx instructions by changing them to plain add instructions, but I didn't try to build the system with the changes. Apparently the regular add op-code can't take two operands of the form -(%ax) as addx can. I looked over my code some more and realized that the extend flag is cleared from an add instruction somewhere above the first addx in each case, so it turns out I can use addx without any problems after all.
Other than that, I don't have much else to report. I haven't had many opportunities to work on Punix for the last couple of months due to family issues. Hopefully I can pick it up again before too long.
I hope your family issues clear up, christop; we're always here if you need someone to talk to, too.  Best of luck getting back to this soon so we can enjoy the eye candy!
Best of luck getting back to this soon so we can enjoy the eye candy!
I've been working on my MC68881 FPU emulator some more this week, and so far I got the fmove, fneg, fabs, fsub, and fadd instructions working. I also timed fadd instructions with a couple different addressing modes. Here's my results with a comparison to a similar floating-point library (the GoFast Fast Floating Point Library). For microsecond timings I'll assume a 25 MHz clock speed. In reality, the TI-68k calcs have 10 or 12MHz CPU's, so these timings should be doubled or more:
fadd.s (d16,An),FPy: 1716 cycles/69us
fadd.x FPx,FPy: 1482 cycles/59us
Double-precision add (GoFast): 48us
Even the fastest time in my emulator is quite a bit slower than the GoFast library's version. However, my emulator has to decode each floating-point instruction before it can execute it, and the fastest instruction in my emulator so far (a conditional branch, FBcc) takes about 500 cycles. Take all that overhead away and I'm almost willing to bet that my fadd would beat the GoFast add operation. I even have my arithmetic operations split out into functions that can be run without decoding overhead. My plain fadd function (which adds two extended-precision values, passed in through registers in a modified IEEE754 internal format) takes around 346 cycles/14us. It doesn't handle infinities yet, but that shouldn't add too many more cycles.
On the other hand, GoFast reportedly can do a multiply in 51us, while mine will take a minimum of 73us without decoding overhead, or 115us with. I think the GoFast times are based on their 32-bit library instead of their 16-bit library. The 68000 only supports 16bit x 16bit multiplications, so multiplying two 64-bit numbers requires 16 multiply instructions. With 32bit x 32bit multiplications, it requires only four multiply instructions.
Besides GoFast, there's also the native TI-AMS floating point operations that would make a good comparison to mine. I actually tested PedroM's implementation since I have the source to find the start and end of the add function. From what I recall, an add operation took over 2000 cycles, and a multiply took over 7000 cycles! Of course, TI-AMS and PedroM use a decimal (BCD) FP format, which is much slower than a binary FP format, so it's not a completely fair comparison. But this also shows that emulating a piece of hardware can still be faster than TI's floating point code. (Before I started writing my fpuemu, I was concerned that full FPU emulation would be much much slower than native software floating point, but that seems not to be the case after all.)
Anyway, that's all for tonight.
fadd.s (d16,An),FPy: 1716 cycles/69us
fadd.x FPx,FPy: 1482 cycles/59us
Double-precision add (GoFast): 48us
Even the fastest time in my emulator is quite a bit slower than the GoFast library's version. However, my emulator has to decode each floating-point instruction before it can execute it, and the fastest instruction in my emulator so far (a conditional branch, FBcc) takes about 500 cycles. Take all that overhead away and I'm almost willing to bet that my fadd would beat the GoFast add operation. I even have my arithmetic operations split out into functions that can be run without decoding overhead. My plain fadd function (which adds two extended-precision values, passed in through registers in a modified IEEE754 internal format) takes around 346 cycles/14us. It doesn't handle infinities yet, but that shouldn't add too many more cycles.
On the other hand, GoFast reportedly can do a multiply in 51us, while mine will take a minimum of 73us without decoding overhead, or 115us with. I think the GoFast times are based on their 32-bit library instead of their 16-bit library. The 68000 only supports 16bit x 16bit multiplications, so multiplying two 64-bit numbers requires 16 multiply instructions. With 32bit x 32bit multiplications, it requires only four multiply instructions.
Besides GoFast, there's also the native TI-AMS floating point operations that would make a good comparison to mine. I actually tested PedroM's implementation since I have the source to find the start and end of the add function. From what I recall, an add operation took over 2000 cycles, and a multiply took over 7000 cycles! Of course, TI-AMS and PedroM use a decimal (BCD) FP format, which is much slower than a binary FP format, so it's not a completely fair comparison. But this also shows that emulating a piece of hardware can still be faster than TI's floating point code.
Anyway, that's all for tonight.
I've been working on my MC68881 FPU emulator some more this week, and so far I got the fmove, fneg, fabs, fsub, and fadd instructions working. I also timed fadd instructions with a couple different addressing modes. Here's my results with a comparison to a similar floating-point library (the GoFast Fast Floating Point Library). For microsecond timings I'll assume a 25 MHz clock speed. In reality, the TI-68k calcs have 10 or 12MHz CPU's, so these timings should be doubled or more:
fadd.s (d16,An),FPy: 1716 cycles/69us
fadd.x FPx,FPy: 1482 cycles/59us
Double-precision add (GoFast): 48us
Even the fastest time in my emulator is quite a bit slower than the GoFast library's version. However, my emulator has to decode each floating-point instruction before it can execute it, and the fastest instruction in my emulator so far (a conditional branch, FBcc) takes about 500 cycles. Take all that overhead away and I'm almost willing to bet that my fadd would beat the GoFast add operation. I even have my arithmetic operations split out into functions that can be run without decoding overhead. My plain fadd function (which adds two extended-precision values, passed in through registers in a modified IEEE754 internal format) takes around 346 cycles/14us. It doesn't handle infinities yet, but that shouldn't add too many more cycles.
On the other hand, GoFast reportedly can do a multiply in 51us, while mine will take a minimum of 73us without decoding overhead, or 115us with. I think the GoFast times are based on their 32-bit library instead of their 16-bit library. The 68000 only supports 16bit x 16bit multiplications, so multiplying two 64-bit numbers requires 16 multiply instructions. With 32bit x 32bit multiplications, it requires only four multiply instructions.
Besides GoFast, there's also the native TI-AMS floating point operations that would make a good comparison to mine. I actually tested PedroM's implementation since I have the source to find the start and end of the add function. From what I recall, an add operation took over 2000 cycles, and a multiply took over 7000 cycles! Of course, TI-AMS and PedroM use a decimal (BCD) FP format, which is much slower than a binary FP format, so it's not a completely fair comparison. But this also shows that emulating a piece of hardware can still be faster than TI's floating point code. (Before I started writing my fpuemu, I was concerned that full FPU emulation would be much much slower than native software floating point, but that seems not to be the case after all.)
Anyway, that's all for tonight.
fadd.s (d16,An),FPy: 1716 cycles/69us
fadd.x FPx,FPy: 1482 cycles/59us
Double-precision add (GoFast): 48us
Even the fastest time in my emulator is quite a bit slower than the GoFast library's version. However, my emulator has to decode each floating-point instruction before it can execute it, and the fastest instruction in my emulator so far (a conditional branch, FBcc) takes about 500 cycles. Take all that overhead away and I'm almost willing to bet that my fadd would beat the GoFast add operation. I even have my arithmetic operations split out into functions that can be run without decoding overhead. My plain fadd function (which adds two extended-precision values, passed in through registers in a modified IEEE754 internal format) takes around 346 cycles/14us. It doesn't handle infinities yet, but that shouldn't add too many more cycles.
On the other hand, GoFast reportedly can do a multiply in 51us, while mine will take a minimum of 73us without decoding overhead, or 115us with. I think the GoFast times are based on their 32-bit library instead of their 16-bit library. The 68000 only supports 16bit x 16bit multiplications, so multiplying two 64-bit numbers requires 16 multiply instructions. With 32bit x 32bit multiplications, it requires only four multiply instructions.
Besides GoFast, there's also the native TI-AMS floating point operations that would make a good comparison to mine. I actually tested PedroM's implementation since I have the source to find the start and end of the add function. From what I recall, an add operation took over 2000 cycles, and a multiply took over 7000 cycles! Of course, TI-AMS and PedroM use a decimal (BCD) FP format, which is much slower than a binary FP format, so it's not a completely fair comparison. But this also shows that emulating a piece of hardware can still be faster than TI's floating point code.
Anyway, that's all for tonight.
Here's a really tiny update.
I've fixed a bunch of little things here and there, mostly with process scheduling. The biggest thing I've done lately is tested running a lot of processes with different nice levels to see how well the scheduler actually handles them and to see if the system stays responsive to user input. Well, it works great if the timeslice is down in the millisecond range (20 ms or less). It works ok if it's in the hundred-or-so millisecond range (100 and up), but response times get very jittery when more than a few busy processes are running at the same time. As expected, a program like "top" gets reeeeally slow when a dozen other processes are running busily in the background.
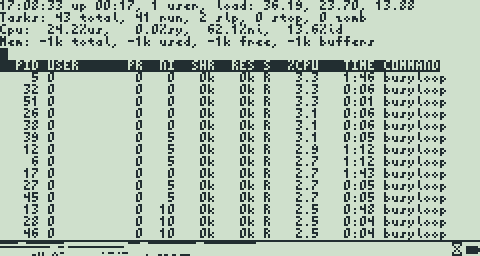
High load. Poor fella.
But the ultimate test of the scheduler was when I played some audio while running more than 40 busy processes in the background, with an even mix of those processes running at nice levels 0, 5, 10, 15, and 19. Yes, I was trying to play audio with a system load average of over 40. Anyway, even under these conditions the audio playback did not skip at all. Having a half-second audio buffer in the driver helps, but it didn't seem necessary since it never went below about 7/16 full. The audio driver wakes up the audio-playing process when the buffer drops to 1/2 (8/16) full, so the process always woke up and topped off the buffer within about 31ms! I'm sure that if I ran the audio player at a higher priority (lower nice value) it would respond even quicker than that. Under normal operating conditions (with only one or two active processes at a time), even that wouldn't be necessary. I might actually reduce the audio buffer size to 125ms or less in order to minimize audio latency, or I might make the buffer size configurable (such as with OSS's SNDCTL_DSP_POLICY ioctl call).
This isn't the end of testing the scheduler and audio driver, though. I'll have to see if they cooperate once I start writing to FlashROM, since that will probably cause relatively long scheduling delays. It'll be a good idea to avoid writing to files while playing audio anyway.
I've fixed a bunch of little things here and there, mostly with process scheduling. The biggest thing I've done lately is tested running a lot of processes with different nice levels to see how well the scheduler actually handles them and to see if the system stays responsive to user input. Well, it works great if the timeslice is down in the millisecond range (20 ms or less). It works ok if it's in the hundred-or-so millisecond range (100 and up), but response times get very jittery when more than a few busy processes are running at the same time. As expected, a program like "top" gets reeeeally slow when a dozen other processes are running busily in the background.
High load. Poor fella.
But the ultimate test of the scheduler was when I played some audio while running more than 40 busy processes in the background, with an even mix of those processes running at nice levels 0, 5, 10, 15, and 19. Yes, I was trying to play audio with a system load average of over 40. Anyway, even under these conditions the audio playback did not skip at all. Having a half-second audio buffer in the driver helps, but it didn't seem necessary since it never went below about 7/16 full. The audio driver wakes up the audio-playing process when the buffer drops to 1/2 (8/16) full, so the process always woke up and topped off the buffer within about 31ms! I'm sure that if I ran the audio player at a higher priority (lower nice value) it would respond even quicker than that. Under normal operating conditions (with only one or two active processes at a time), even that wouldn't be necessary. I might actually reduce the audio buffer size to 125ms or less in order to minimize audio latency, or I might make the buffer size configurable (such as with OSS's SNDCTL_DSP_POLICY ioctl call).
This isn't the end of testing the scheduler and audio driver, though. I'll have to see if they cooperate once I start writing to FlashROM, since that will probably cause relatively long scheduling delays. It'll be a good idea to avoid writing to files while playing audio anyway.
Quote:
This isn't the end of testing the scheduler and audio driver, though. I'll have to see if they cooperate once I start writing to FlashROM, since that will probably cause relatively long scheduling delays. It'll be a good idea to avoid writing to files while playing audio anyway.
Indeed, writing to Flash memory will cause scheduling delays of hundreds of milliseconds, possibly more than a second.
This would hold even if you used the fast write mode of the Flash chip, which AMS doesn't use. I don't remember whether PedroM uses it, or whether anyone ever used it on TI-68k calcs... I'd say, ask PpHd or ExtendeD
I'm going to be writing to Flash in blocks of 128 bytes at a time, so it won't block for more than some tens of milliseconds at the most (except for erasing pages, for which the datasheet says 0.56 seconds is typical, and 10 seconds is the maximum :/).
Is the fast write mode the same as the Multi Word/Byte Write mode? That command allows writing up to 32 bytes at a time, which would be very useful for faster write speeds.
Is the fast write mode the same as the Multi Word/Byte Write mode? That command allows writing up to 32 bytes at a time, which would be very useful for faster write speeds.

: Prizm Runner-Up")

If the flash chip's fast mode is similar to the 8x's flash chip, then the fast mode (aka unlock bypass) simply means that you don't have to write the unlock sequence all of the time. The writing speed is the same, you just don't have to write as many times to flash data.
GlassOS uses fast programming mode and has no issues. I cannot say if there is a difference as I never had a multibyte flash routine before. :-X
GlassOS uses fast programming mode and has no issues. I cannot say if there is a difference as I never had a multibyte flash routine before. :-X
Register to Join the Conversation
You cannot post new topics in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot vote in polls in this forum
You cannot reply to topics in this forum
You cannot edit your posts in this forum
You cannot delete your posts in this forum
You cannot vote in polls in this forum
Advertisement