


- Alien Breed 5 Episode III: Impact
- 21 Dec 2015 08:37:29 am
- Last edited by JamesV on 11 Nov 2021 09:51:16 pm; edited 2 times in total
EDIT: Version 3.0.0 is now complete and available for download:
TI-84 Plus CE download
TI-83/TI-84 Plus download
Original post:
Since 3.5 years ago when I decided to do Alien Breed 5, I've had a rough plan in my head for it to be a 3-part game, ie. the first main release, followed by two additional campaigns with new features to be added later. I've recently started working on the 3rd and (most likely) final part. It's still very early days, but I've already gotten a few cool things done.
As usual, there will be a new campaign, although it will be different in structure to Episodes I & II. There will also be new gameplay elements, some new enemies, more achievements and potentially some slight graphics tweaks in the form of more tile animations.
So far, I've reworked the level file format to allow for some of the additional gameplay elements, which will allow for more things to happen in levels. The level editor pretty much had to be rebuilt from scratch, as well as making a simple program to convert the existing Episode I & II data to the new format. I'm now halfway through implementing the calculator-side changes to all of this, so that the game correctly interprets the new level format and starts incorporating the new elements.
Additionally, whilst this will still include the standard TI-83+/84+ flash application release, over the last 36 hours I've been doing some tests to see how viable it would be to include a build for the TI-84+CE!
I've drawn inspiration from MateoConLechuga's Mono2Color project for the TI-84+CSE, and after a few experiments determined that I'll most likely have to stick with monochrome tiles & sprites so that I can run the LCD in 1bpp mode, otherwise the frame rate gets way too slow. Below you can view a demonstration showing the game in 3 different zoom levels (x1, x2 & x3). As you'll see, x1 moves super quick, x2 moves roughly the same speed as the TI-83+/84+ monochrome version (within 1fps), and x3 is a bit slower again (around 7-8fps slower). Of course this demo only includes the scrolling background, no player/enemy/gunfire sprites. However, all the tile drawing & sprite rendering is done on a 768 byte buffer, the part that slows things down is scaling this 96x64 resolution buffer up to either 192x128 (x2) or 288x192 (x3). I'm confident that drawing the sprites over the tilemap will have minimal effect with the CPU speed of the TI-84+CE (but this will be my next few experiments).
The 768 video buffer -> vram drawing/scaling routines were written fairly quickly, so I might be able to optimise them a little. I'll continue playing around and see how I can improve it. At the very least, I'd like to have a TI-84+CE version with a play screen of 192x128.
TI-84 Plus CE download
TI-83/TI-84 Plus download
Original post:
Since 3.5 years ago when I decided to do Alien Breed 5, I've had a rough plan in my head for it to be a 3-part game, ie. the first main release, followed by two additional campaigns with new features to be added later. I've recently started working on the 3rd and (most likely) final part. It's still very early days, but I've already gotten a few cool things done.
As usual, there will be a new campaign, although it will be different in structure to Episodes I & II. There will also be new gameplay elements, some new enemies, more achievements and potentially some slight graphics tweaks in the form of more tile animations.
So far, I've reworked the level file format to allow for some of the additional gameplay elements, which will allow for more things to happen in levels. The level editor pretty much had to be rebuilt from scratch, as well as making a simple program to convert the existing Episode I & II data to the new format. I'm now halfway through implementing the calculator-side changes to all of this, so that the game correctly interprets the new level format and starts incorporating the new elements.
Additionally, whilst this will still include the standard TI-83+/84+ flash application release, over the last 36 hours I've been doing some tests to see how viable it would be to include a build for the TI-84+CE!
I've drawn inspiration from MateoConLechuga's Mono2Color project for the TI-84+CSE, and after a few experiments determined that I'll most likely have to stick with monochrome tiles & sprites so that I can run the LCD in 1bpp mode, otherwise the frame rate gets way too slow. Below you can view a demonstration showing the game in 3 different zoom levels (x1, x2 & x3). As you'll see, x1 moves super quick, x2 moves roughly the same speed as the TI-83+/84+ monochrome version (within 1fps), and x3 is a bit slower again (around 7-8fps slower). Of course this demo only includes the scrolling background, no player/enemy/gunfire sprites. However, all the tile drawing & sprite rendering is done on a 768 byte buffer, the part that slows things down is scaling this 96x64 resolution buffer up to either 192x128 (x2) or 288x192 (x3). I'm confident that drawing the sprites over the tilemap will have minimal effect with the CPU speed of the TI-84+CE (but this will be my next few experiments).
The 768 video buffer -> vram drawing/scaling routines were written fairly quickly, so I might be able to optimise them a little. I'll continue playing around and see how I can improve it. At the very least, I'd like to have a TI-84+CE version with a play screen of 192x128.










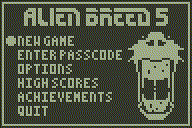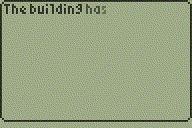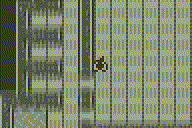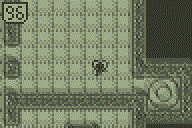
: 2nd Place")










