Last edited by AHelper on 01 Sep 2016 12:41:23 am; edited 1 time in total
More progress. So, maps are a bit picky, as gcc has issues with constexpr mode. A large issue right now are fuzzy comparisons. I have seen errors up to 0.000001 difference when line-plane collision vertex order is swapped :S Fixed this by sorting vertices.
I have fixed errors in my model loader, removed faulty comparisons, and hey, look what complex cutting I have!
The plane actually cut through two parts of suzanne, the head and right ear. Because I care about edge loops, only the loop surrounding the current cell is used.
Current issues: triangles can overlap. Not sure how to fix since normal collision will not work. You can see the error by the cutting plane (red) has yellow selected parts but aren't red (poking through her head).
Last edited by AHelper on 01 Sep 2016 12:41:23 am; edited 1 time in total
After a bunch of failings with index and vertex storage in vectors, I now generated ONE cell!
The last image shows a bunch of z-fighting on the cell face. This is because I don't know how to properly triangulate the edge loop. By that I mean I don't know how to prevent a triangle from generating on top of another or outsize of the edge loop. I had code to fix some of it, but doesn't seem to work on its own.
WOOT!
Next would be to add in code to actually generate the points using an in-house random number generator, generate the points, generate the cell midpoints, and generate ALL cells and export each one. Then is UV mapping for the cell faces and adjusting UV coords for the original trimesh (since new triangles are generated).
After that, OpenCL needs to happen, this uses a LOT of brute-force math and data manipulation. I could try to cache certain slices, but meh, this works, and I don't want to get it mad.
Last edited by AHelper on 01 Sep 2016 12:41:23 am; edited 1 time in total
After moving all of my code to a library setup, rewriting quite a bit, and losing internet, I got down to a tessellation library which generates all cells, more robust, and accepts a seed for a mersenne twister built-in. That was Saturday and was generating large mesh output data and was taking ~28 seconds for a 4.6K face 2.3K vertex torus.
Today, I was rewriting large parts and optimizing the hell out of it without going to OpenCL. Well, I now am down to 0.20 seconds (with 0.04 to write the output to a file, not needed) to generate 14 cells on the same torus. Now, this is 0.2 seconds for a high-resolution model, this is overkill for the models I will give it in production code.
SCREENIE:
(I may be gone from the internet for a while, so I will be working on finally getting the instancing system. Dumping the serialize data looks ok so far, working out the deserialization part and will then work towards replacing the existing code)
(Also, the voronoi code should be released as a separate LGPL library once done, woo)
Well, this is just great. I just got a lot of progress on my instancing system, getting things to sync up and such... Now I have major design issues.
Perfect.
Main problem is circular header includes as classes have cyclical dependencies. Resources can contain multiple instances. Instances point to 0 or 1 resources. No issues with headers here, the problem is accessing their collections, those complicate things.
Anyone here used ElementTree in python (either xml or lxml) that had to deal with namespaces? I am trying to find elements in a collada file, which specifies a namespace. With lxml.etree, it realizes that the default namespace is http://www.collada.org/2005/11/COLLADASchema, but the code examples from the API documentation for root.find('{http://www.collada.org/2005/11/COLLADASchema}COLLADA') fail. I can't get anything useful out.
Anyone have a recommendation for a minimalist xml library for python that doesn't care about namespaces?
I too have had namespace issues with lxml. elfprince13 wrote some code to parse shaun's Tokens.xml file. I believe there was a routine in there that took namespaces into account. It's on the last page of this topic.
Currently I am using xml.dom.minidom to parse the collada file, which is close to what I do in C++ (tinyxml2). Would have liked XPath support, but doesn't matter, I just pulled stuff from C++ into python as the API is nearly identical.
Work on the new GUI system is underway. This GUI is not integrated into the client code, so it should be easier for me to add it into the server daemon if need be. Unlike the old GUI code using SDL, this library relies on GL to render everything. Why? Alpha blending on SDL is broken a bit. Also, there is a chance that I will write a GL-based SVG renderer with animation support (Didn't find any that are still active/working. If you find something that allows SVG with animations that render in a GL3 core context, I would love to hear about it).
I will be able to post screenies as different components are completed (or YT if I can get animations in).
GUi system is getting a motion system created that will allow different properties to be animated, such as doing a soft glow around the edges of selected elements or the scaling/animated construction of dialogs. Right now, properties can be animated and queued up. I will work on different types of interpolation as well as making a cursor for mouse-based input.
However, I am seeing a very strange problem that I have encountered before: When rendering, I am occasionally seeing frames "skipped", meaning that a frame will not render anything. I do a glClear which sets to black, so I see flashes of black, but this isn't limited to after a clear - This can happen when I do something like render to a FBO for shader post-FX. Not sure if a GL error shows up or not, will need to reduce debug output per-frame.
<edit>
Don't worry about the above, for some reason I turned double buffering off -_-. Works fine now.
Finally got win64 builds of Redintegrate to be finished. I have yet to test them on Windows, but they should work fine. I already had a win32 build system set up, but I don't have access to that system any more. I only overwrote my Linux Lua with the win64 build once, so all is well.
Sadly my mingw64 doesn't have std::to_string (I am out-of-date), so a bit of hacking was needed from cmake/config.h.
Finally got win64 builds of Redintegrate to be finished. I have yet to test them on Windows, but they should work fine. I already had a win32 build system set up, but I don't have access to that system any more. I only overwrote my Linux Lua with the win64 build once, so all is well.
Sadly my mingw64 doesn't have std::to_string (I am out-of-date), so a bit of hacking was needed from cmake/config.h.
That's still pretty minor in terms of getting a full 64-bit build working, in my opinion. Congratulations on the progress!
My GUI system gooey finally has an animated cursor that can be moved around! So far the motion (value lerping) system is working fine for animating various elements, such as the cursor and text (for testing). Unlike the previous GUI code which used SDL2, this code uses OpenGL to render. Alpha blending works unlike in SDL2 (main reason for switching).
Right now, with about 4-8 animations running, the GUI runs smoothly at 60FPS with 1-1.3% CPU usage.
Fun facts, loading resources for this gooey test uses 29,000 mallocs and the mcount function is called 12,000,000+ times. (mallocs, not much of a performance bottleneck. mcount is gcc profiling)
Last edited by AHelper on 01 Sep 2016 12:41:23 am; edited 1 time in total
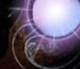
So, here's my problem:
Look at the partial red ring and blue dot. I have blurring, but I am having problems doing it. Right now, I have a Gaussian shader running on the vertical then horizontal. But... looking at the image, the horizontal seems to be doing weird things. I have blending on with glBlendFuncSeparate(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA,GL_ONE,GL_ONE_MINUS_SRC_ALPHA); as that seemed to help me out.
I am thinking that my problem lies in the fact that I have a dark 1px border on the images blurred, that is why flat sides look messed up in the blur. Possibly having a glow texture might help...
Thanks to HCWP and a nice sprint to get some OpenCL code written by myself, I have the basis for a compute library that will use either a kernel running through OpenCL or a fallback function on the CPU without OpenCL. Main reason was that I have segments of code where I don't want to deal with OpenCL and no OpenCL, yet keeping the code very similar.
This will lead to libvoronoi getting OpenCL support and have larger optimizations done on it regardless of using CL.
Here is some niceness for my Compute helper code testing: Code:
int main(int argc, char **argv)
{
string input = "Hello world from AHelper0's GTX 550 Ti from OpenCL";
char output[256];
// Make Task, Context is auto-created as Singleton
Task test("Test task", "../src/test5/test.cl", true, "main", testCPU);
// Input arguments
test.setArgument(input.size()+1, (void*)input.data(), CL_MEM_COPY_HOST_PTR | CL_MEM_READ_ONLY);
// Output arguments
test.setReturn(256, output, CL_MEM_WRITE_ONLY);
// Dimensions
test.setWorkItems(1, input.size()+1);
// Run it
test.start();
test.join();
test.end();
// Check results
cout << output << endl;
}
The OpenCL kernel in test.cl: Code:
__kernel void main(__global char *in, __global char *out)
{
unsigned int i = get_global_id(0);
out[i] = in[i];
}
And the output: Code:
![HAL@HAL build]$ ./test5
Compute::Compute(): Loaded libOpenCL.so
Compute::Compute(): Detected 1 device(s):
GeForce GTX 550 Ti
Compute library initialized
Hello world from AHelper0's GTX 550 Ti from OpenCL
Compute library unloaded
The compute library uses CLEW to dynamically load in an OpenCL library on the deployed system, both Windows and Linux. Compute lets me easily make tasks, run them asynchronously, and get the output very easily. At the same time, it provides a native fallback in case CLEW fails to load OpenCL (no driver or other error), encounters an error setting up an OpenCL context, or if a Task throws an error (disables OpenCL in that Task alone).
Right now, I don't have the CPU callback actually finished, only thing left is to spawn the workers (spawns threaded workers and blocks until all are spawned, not finished. Limits thread count by cores available. Maybe have it all asynch and have a master thread to spawn workers?)
My main drive for getting this is that I want to easily spot-optimize code in Redintegrate and libvoronoi and not have to care if OpenCL is supported or not and allowing fallbacks in case something goes wrong.
Register to Join the Conversation
Have your own thoughts to add to this or any other topic? Want to ask a question, offer a suggestion, share your own programs and projects, upload a file to the file archives, get help with calculator and computer programming, or simply chat with like-minded coders and tech and calculator enthusiasts via the site-wide AJAX SAX widget? Registration for a free Cemetech account only takes a minute.
You cannot post new topics in this forum You cannot reply to topics in this forum You cannot edit your posts in this forum You cannot delete your posts in this forum You cannot vote in polls in this forum


: Prizm Runner-Up")










: TI Runner-Up")










